レンタルオフィス | Attention: Deepseek
ページ情報
投稿人 Selma 메일보내기 이름으로 검색 (138.♡.139.35) 作成日25-02-03 21:46 閲覧数3回 コメント0件本文
Address :
MC
 Deepseek says it has been in a position to do this cheaply - researchers behind it claim it price $6m (£4.8m) to train, a fraction of the "over $100m" alluded to by OpenAI boss Sam Altman when discussing GPT-4. Testing: Google examined out the system over the course of 7 months throughout 4 workplace buildings and with a fleet of at occasions 20 concurrently controlled robots - this yielded "a collection of 77,000 real-world robotic trials with both teleoperation and autonomous execution". The workshop contained "a suite of challenges, including distance estimation, (embedded) semantic & panoptic segmentation, and image restoration. C-Eval: A multi-degree multi-self-discipline chinese language analysis suite for basis models. A span-extraction dataset for Chinese machine reading comprehension. HellaSwag: Can a machine actually end your sentence? You may then use a remotely hosted or SaaS mannequin for the other experience. We report the skilled load of the 16B auxiliary-loss-primarily based baseline and the auxiliary-loss-free model on the Pile check set. Researchers with Align to Innovate, the Francis Crick Institute, Future House, and the University of Oxford have built a dataset to test how effectively language fashions can write biological protocols - "accurate step-by-step instructions on how to complete an experiment to perform a selected goal".
Deepseek says it has been in a position to do this cheaply - researchers behind it claim it price $6m (£4.8m) to train, a fraction of the "over $100m" alluded to by OpenAI boss Sam Altman when discussing GPT-4. Testing: Google examined out the system over the course of 7 months throughout 4 workplace buildings and with a fleet of at occasions 20 concurrently controlled robots - this yielded "a collection of 77,000 real-world robotic trials with both teleoperation and autonomous execution". The workshop contained "a suite of challenges, including distance estimation, (embedded) semantic & panoptic segmentation, and image restoration. C-Eval: A multi-degree multi-self-discipline chinese language analysis suite for basis models. A span-extraction dataset for Chinese machine reading comprehension. HellaSwag: Can a machine actually end your sentence? You may then use a remotely hosted or SaaS mannequin for the other experience. We report the skilled load of the 16B auxiliary-loss-primarily based baseline and the auxiliary-loss-free model on the Pile check set. Researchers with Align to Innovate, the Francis Crick Institute, Future House, and the University of Oxford have built a dataset to test how effectively language fashions can write biological protocols - "accurate step-by-step instructions on how to complete an experiment to perform a selected goal".
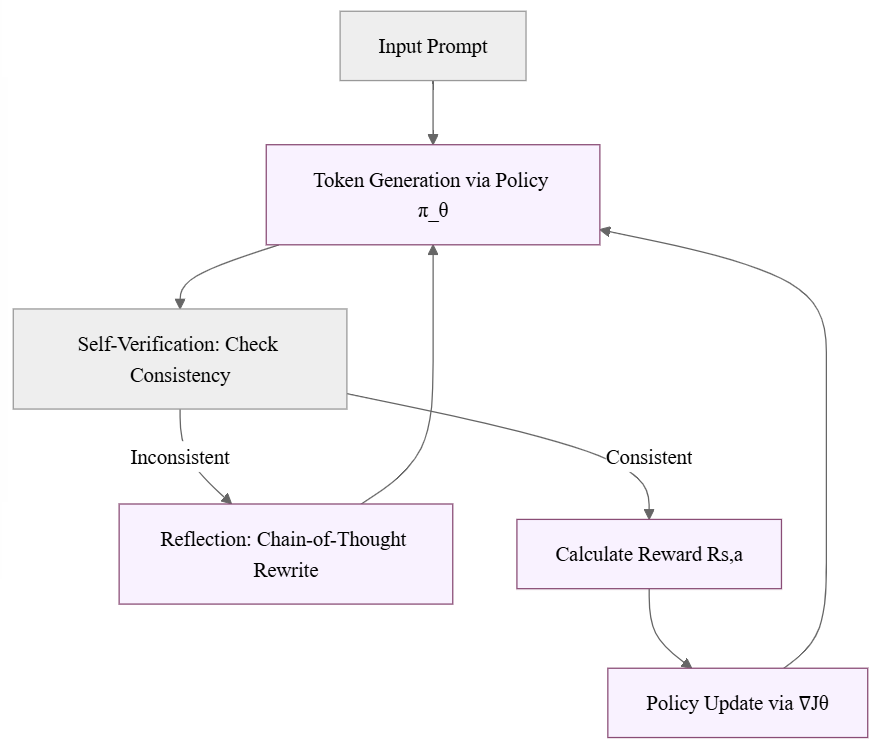 REBUS problems really a helpful proxy test for a general visual-language intelligence? Deepseek-coder: When the large language mannequin meets programming - the rise of code intelligence. DeepSeek persistently adheres to the route of open-supply models with longtermism, aiming to steadily approach the final word goal of AGI (Artificial General Intelligence). Further exploration of this method throughout different domains remains an essential course for future analysis. While our present work focuses on distilling data from arithmetic and coding domains, this method shows potential for broader applications throughout varied activity domains. One thing to take into consideration because the strategy to building quality training to teach people Chapel is that for the time being one of the best code generator for different programming languages is Deepseek Coder 2.1 which is freely accessible to use by folks. Massive Training Data: Trained from scratch on 2T tokens, together with 87% code and 13% linguistic data in both English and Chinese languages. However the DeepSeek growth could level to a path for the Chinese to catch up more shortly than beforehand thought. It’s considerably more efficient than different models in its class, gets great scores, and the research paper has a bunch of details that tells us that DeepSeek has built a crew that deeply understands the infrastructure required to practice formidable models.
REBUS problems really a helpful proxy test for a general visual-language intelligence? Deepseek-coder: When the large language mannequin meets programming - the rise of code intelligence. DeepSeek persistently adheres to the route of open-supply models with longtermism, aiming to steadily approach the final word goal of AGI (Artificial General Intelligence). Further exploration of this method throughout different domains remains an essential course for future analysis. While our present work focuses on distilling data from arithmetic and coding domains, this method shows potential for broader applications throughout varied activity domains. One thing to take into consideration because the strategy to building quality training to teach people Chapel is that for the time being one of the best code generator for different programming languages is Deepseek Coder 2.1 which is freely accessible to use by folks. Massive Training Data: Trained from scratch on 2T tokens, together with 87% code and 13% linguistic data in both English and Chinese languages. However the DeepSeek growth could level to a path for the Chinese to catch up more shortly than beforehand thought. It’s considerably more efficient than different models in its class, gets great scores, and the research paper has a bunch of details that tells us that DeepSeek has built a crew that deeply understands the infrastructure required to practice formidable models.
Language fashions are multilingual chain-of-thought reasoners. Instruction-following evaluation for giant language models. DeepSeek-AI (2024c) DeepSeek-AI. Deepseek-v2: A powerful, economical, and efficient mixture-of-consultants language mannequin. The verified theorem-proof pairs have been used as artificial information to nice-tune the DeepSeek-Prover mannequin. Besides, we attempt to arrange the pretraining data at the repository stage to boost the pre-skilled model’s understanding capability within the context of cross-information within a repository They do this, by doing a topological kind on the dependent information and appending them into the context window of the LLM. There may be more knowledge than we ever forecast, they informed us. Secondly, though our deployment strategy for DeepSeek-V3 has achieved an finish-to-end technology speed of greater than two times that of DeepSeek-V2, there still stays potential for additional enhancement. However, in additional normal eventualities, constructing a feedback mechanism by way of laborious coding is impractical. Import AI runs on lattes, ramen, and suggestions from readers. Jack Clark Import AI publishes first on Substack DeepSeek makes the very best coding mannequin in its class and releases it as open source:… Clark et al. (2018) P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord.
Most of his desires were strategies blended with the remainder of his life - video games performed towards lovers and lifeless kin and enemies and competitors. John Muir, the Californian naturist, was said to have let out a gasp when he first saw the Yosemite valley, seeing unprecedentedly dense and love-stuffed life in its stone and timber and wildlife. Autonomy assertion. Completely. If they have been they'd have a RT service in the present day. To make sure optimum performance and suppleness, now we have partnered with open-source communities and hardware distributors to supply a number of methods to run the mannequin regionally. Think you could have solved question answering? NVIDIA (2024a) NVIDIA. Blackwell architecture. Wang et al. (2024a) L. Wang, H. Gao, C. Zhao, X. Sun, and D. Dai. Li et al. (2023) H. Li, Y. Zhang, F. Koto, Y. Yang, H. Zhao, Y. Gong, N. Duan, and T. Baldwin. Rouhani et al. (2023b) B. D. Rouhani, R. Zhao, A. More, M. Hall, A. Khodamoradi, S. Deng, D. Choudhary, M. Cornea, E. Dellinger, K. Denolf, et al. FP8 codecs for deep studying.
【コメント一覧】
コメントがありません.
