不動産売買 | How To turn Your Deepseek From Zero To Hero
ページ情報
投稿人 Fawn Gallard 메일보내기 이름으로 검색 (138.♡.121.134) 作成日25-02-01 14:54 閲覧数2回 コメント0件本文
Address :
NO
 Meaning DeepSeek was ready to attain its low-price model on beneath-powered AI chips. The stunning achievement from a comparatively unknown AI startup becomes even more shocking when contemplating that the United States for years has labored to restrict the provision of high-power AI chips to China, citing nationwide security issues. Sam Altman, CEO of OpenAI, final year said the AI trade would want trillions of dollars in investment to help the development of in-demand chips wanted to energy the electricity-hungry information centers that run the sector’s complex fashions. Programs, alternatively, are adept at rigorous operations and can leverage specialized tools like equation solvers for complex calculations. Here’s a lovely paper by researchers at CalTech exploring one of the unusual paradoxes of human existence - regardless of being able to course of an enormous amount of advanced sensory information, humans are literally fairly slow at pondering. America could have purchased itself time with restrictions on chip exports, but its AI lead simply shrank dramatically despite these actions.
Meaning DeepSeek was ready to attain its low-price model on beneath-powered AI chips. The stunning achievement from a comparatively unknown AI startup becomes even more shocking when contemplating that the United States for years has labored to restrict the provision of high-power AI chips to China, citing nationwide security issues. Sam Altman, CEO of OpenAI, final year said the AI trade would want trillions of dollars in investment to help the development of in-demand chips wanted to energy the electricity-hungry information centers that run the sector’s complex fashions. Programs, alternatively, are adept at rigorous operations and can leverage specialized tools like equation solvers for complex calculations. Here’s a lovely paper by researchers at CalTech exploring one of the unusual paradoxes of human existence - regardless of being able to course of an enormous amount of advanced sensory information, humans are literally fairly slow at pondering. America could have purchased itself time with restrictions on chip exports, but its AI lead simply shrank dramatically despite these actions.
Unlike prefilling, attention consumes a larger portion of time in the decoding stage. They modified the usual consideration mechanism by a low-rank approximation called multi-head latent attention (MLA), and used the mixture of specialists (MoE) variant beforehand revealed in January. This success may be attributed to its advanced knowledge distillation approach, which effectively enhances its code generation and problem-solving capabilities in algorithm-centered tasks. Let’s just give attention to getting an important mannequin to do code era, to do summarization, to do all these smaller duties. For now, the prices are far larger, as they contain a combination of extending open-source tools like the OLMo code and poaching costly employees that may re-remedy issues on the frontier of AI. In some methods, DeepSeek was far less censored than most Chinese platforms, offering solutions with keywords that would typically be shortly scrubbed on domestic social media. Given the issue problem (comparable to AMC12 and AIME exams) and the particular format (integer answers only), we used a combination of AMC, AIME, and Odyssey-Math as our downside set, removing a number of-selection choices and filtering out issues with non-integer solutions.
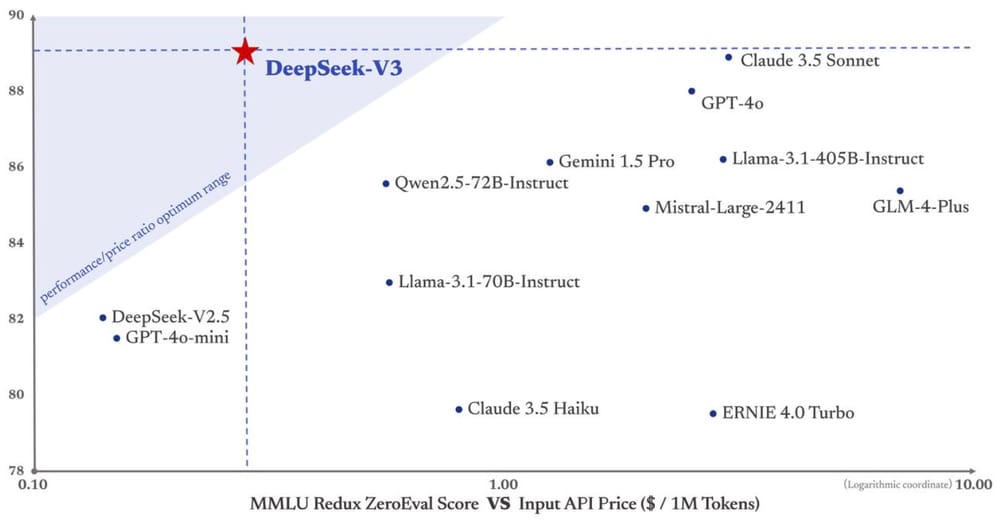
Testing: Google examined out the system over the course of 7 months throughout four office buildings and with a fleet of at occasions 20 concurrently controlled robots - this yielded "a collection of 77,000 real-world robotic trials with each teleoperation and autonomous execution". I determined to test it out. We used the accuracy on a chosen subset of the MATH take a look at set as the analysis metric. 3. Train an instruction-following mannequin by SFT Base with 776K math issues and their software-use-integrated step-by-step solutions. We prompted GPT-4o (and DeepSeek-Coder-V2) with few-shot examples to generate 64 options for every problem, retaining people who led to correct solutions. Benchmark tests put V3’s performance on par with GPT-4o and Claude 3.5 Sonnet. To ensure unbiased and thorough efficiency assessments, DeepSeek AI designed new drawback units, such because the Hungarian National High-School Exam and Google’s instruction following the evaluation dataset. Meta (META) and Alphabet (GOOGL), Google’s dad or mum company, had been also down sharply. Why don’t you're employed at Meta? Asked about sensitive topics, the bot would start to answer, then stop and delete its own work. Our last options were derived via a weighted majority voting system, which consists of producing multiple solutions with a policy model, assigning a weight to each solution utilizing a reward model, after which selecting the reply with the very best total weight.
9. If you want any custom settings, set them after which click on Save settings for this model adopted by Reload the Model in the top proper. To maintain a stability between model accuracy and computational effectivity, we fastidiously selected optimum settings for DeepSeek-V3 in distillation. DeepSeek-V3 uses considerably fewer sources compared to its friends; for example, whereas the world's leading A.I. Slightly completely different from DeepSeek-V2, DeepSeek-V3 uses the sigmoid perform to compute the affinity scores, and applies a normalization amongst all chosen affinity scores to produce the gating values. Our remaining options have been derived by means of a weighted majority voting system, the place the answers were generated by the policy model and the weights have been determined by the scores from the reward mannequin. The initiative helps AI startups, knowledge centers, and domain-particular AI options. Specifically, we paired a policy model-designed to generate problem options within the form of computer code-with a reward model-which scored the outputs of the coverage model. Specifically, whereas the R1-generated data demonstrates sturdy accuracy, it suffers from issues corresponding to overthinking, poor formatting, and excessive size. • We are going to persistently discover and iterate on the deep pondering capabilities of our models, aiming to boost their intelligence and drawback-fixing talents by increasing their reasoning length and depth.
If you liked this posting and you would like to get much more details regarding deepseek ai china; https://linktr.ee/deepseek1, kindly check out our page.
【コメント一覧】
コメントがありません.
